
Authors:
(1) Nora Schneider, Computer Science Department, ETH Zurich, Zurich, Switzerland ([email protected]);
(2) Shirin Goshtasbpour, Computer Science Department, ETH Zurich, Zurich, Switzerland and Swiss Data Science Center, Zurich, Switzerland ([email protected]);
(3) Fernando Perez-Cruz, Computer Science Department, ETH Zurich, Zurich, Switzerland and Swiss Data Science Center, Zurich, Switzerland ([email protected]).
Table of Links
2 Background
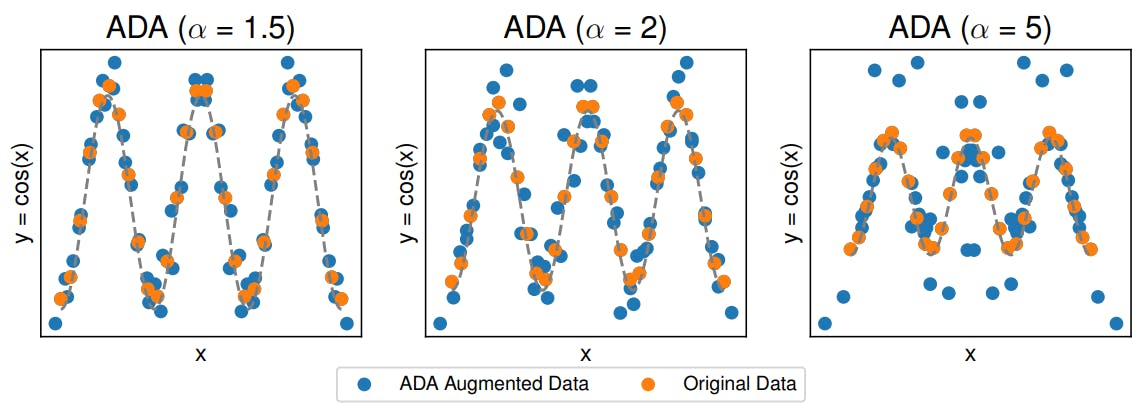
3.1 Comparison to C-Mixup and 3.2 Preserving nonlinear data structure
4 Experiments and 4.1 Linear synthetic data
4.2 Housing nonlinear regression
4.3 In-distribution Generalization
4.4 Out-of-distribution Robustness
5 Conclusion, Broader Impact, and References
A Additional information for Anchor Data Augmentation
4.4 Out-of-distribution Robustness
In this section, we evaluate the performance of ADA and compare it to prior approaches on tasks involving out-of-distribution robustness. We use the same datasets as [49] and closely follow their experimental setup.
Data: We use four of the five out-of-distribution datasets used in [49]. First, we use RCFashionMNIST (RCF-MNIST) [49], which is a synthetic modification of Fashion-MNIST that models subpopulation shifts. Second, we investigate domain shifts using Communities and Crime (Crime) [12], SkillCraft1 Master Table (SkillCraft) [12] and Drug-target Interactions (DTI) [17] all of which are tabular datasets. For Crime, we use state identification, in SkillCraft we use "League Index", which corresponds to different levels of competitors, and in DTI we use year, as domain information. We split the datasets into train-, validation- and test data based on the domain information resulting in domain-distinct datasets. We provide a detailed description of datasets in Appendix B.4. Due to computational complexity, we could not establish a fair comparison on the satellite image regression dataset [23] (the fifth dataset in [49]), so we report some exploratory results in Appendix B.4.
Models and comparisons: As detailed in Section 4.3. Additionally, we use a ResNet-18 [15] for RCF-MNIST and DeepDTA [38] for DTI, as proposed in [49].
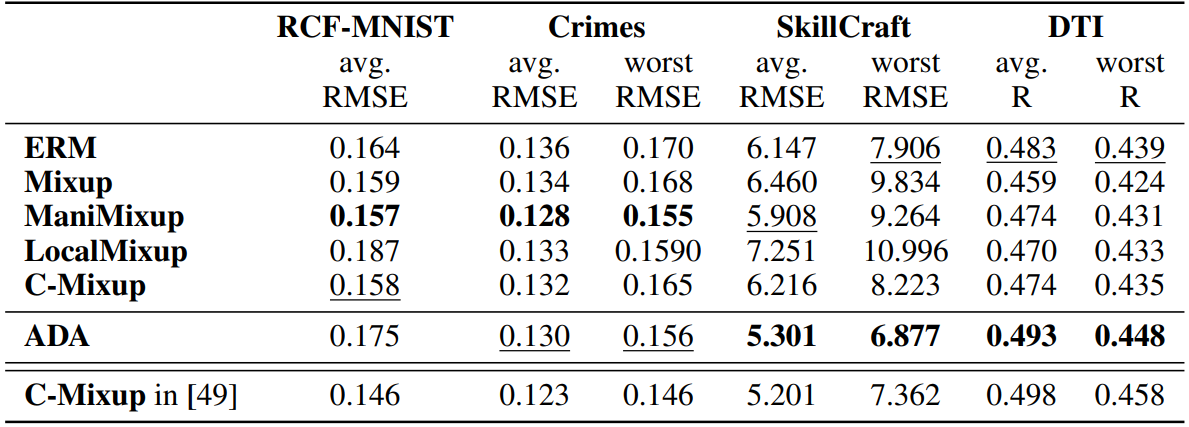
Results: We report the RMSE and the "worst" domain RMSE, which corresponds to the worst within-domain RMSE for out-of-domain test sets in Table 2. Similar to [49], we report the R value for the DTI dataset (higher values suggest a better fit of the regression model). For full transparency, in the last row, we copy the results from [49]. We can assess that ADA is competitive with C-Mixup and the other data augmentation strategies. Under the same conditions (split of data and Neural network structure), ADA is superior to C-Mixup. But, the degree of improvement is marginal on some datasets and as we show in the last row, we could not fully replicate their results. ADA is significantly better than C-Mixup and other strategies on the SkillCraft data, in which ADA reduces the error by around 15% compared to the ERM solution.
This paper is available on arxiv under CC0 1.0 DEED license.