
Authors:
(1) Jianhui Pang, from the University of Macau, and work was done when Jianhui Pang and Fanghua Ye were interning at Tencent AI Lab ([email protected]);
(2) Fanghua Ye, University College London, and work was done when Jianhui Pang and Fanghua Ye were interning at Tencent AI Lab ([email protected]);
(3) Derek F. Wong, University of Macau;
(4) Longyue Wang, Tencent AI Lab, and corresponding author.
Table of Links
3 Anchor-based Large Language Models
3.2 Anchor-based Self-Attention Networks
4 Experiments and 4.1 Our Implementation
4.2 Data and Training Procedure
7 Conclusion, Limitations, Ethics Statement, and References
Abstract
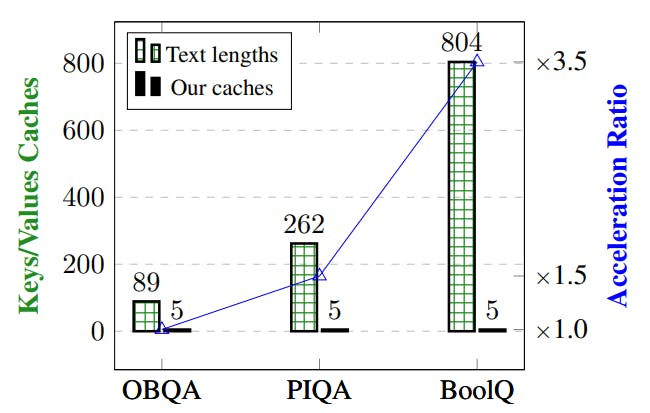
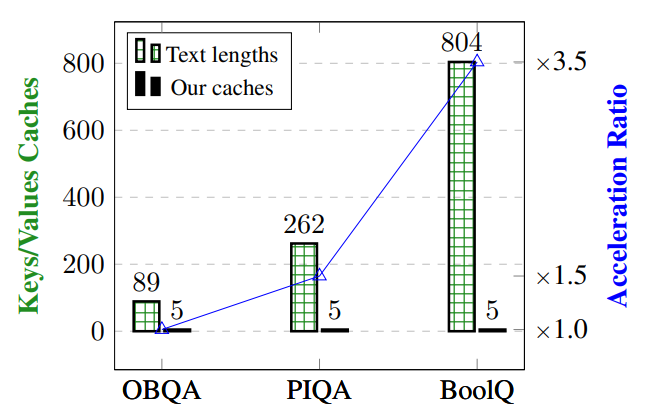
Large language models (LLMs) predominantly employ decoder-only transformer architectures, necessitating the retention of keys/values information for historical tokens to provide contextual information and avoid redundant computation. However, the substantial size and parameter volume of these LLMs require massive GPU memory. This memory demand increases with the length of the input text, leading to an urgent need for more efficient methods of information storage and processing. This study introduces Anchor-based LLMs (AnLLMs), which utilize an innovative anchor-based self-attention network (AnSAN) and also an anchor-based inference strategy. This approach enables LLMs to compress sequence information into an anchor token, reducing the keys/values cache and enhancing inference efficiency. Experiments on question-answering benchmarks reveal that AnLLMs maintain similar accuracy levels while achieving up to 99% keys/values cache reduction and up to 3.5 times faster inference. Despite a minor compromise in accuracy, the substantial enhancements of AnLLMs employing the AnSAN technique in resource utilization and computational efficiency underscore their potential for practical LLM applications.
1 Introduction
Large language models (LLMs) primarily utilize decoder-only transformer architectures, which necessitate caching keys/values information for historical tokens during the auto-regressive inference to supply contextual information and avoid redundant computation (Wei et al., 2022; Touvron et al., 2023a; OpenAI, 2023; Touvron et al., 2023b). However, due to their immense size and high parameter count, a considerable amount of GPU memory is required for loading. Furthermore, as the length
of input text grows, storing keys/values caches requires more and more GPU memory, as evidenced in in-context learning, complex instructions, and extended conversations (Dong et al., 2022; Jiang et al., 2023; Wang et al., 2023), which is not conducive to scenarios with limited computational resources. An alternative approach entails recalculating these extensive inputs, which, however, results in increased time overhead. Therefore, this study aims to reduce the storage demand for keys/values caches during the inference phase of LLMs, improving the memory efficiency and, consequently, accelerating the inference speed as well.
In a recent study, Wang et al. (2023) demonstrate that label words in prefix demonstrations can act as anchors during inference, providing an effective context compression approach for improving inference efficiency in in-context learning. However, in practical applications, not all prefix inputs or demonstrations contain label words suitable for compressing information, making the reliance on label words a less universal approach for text information compression. Additionally, Pang et al. (2024) observe that LLMs tend to attend to only a few, yet consistent, prefix tokens during inference. However, the specific tokens utilized are often unpredictable and uncontrollable. These observations raise an intriguing question: do natural language texts contain anchor points that compress the overall semantic information of sequences? In this context, previous studies on sequence embeddings have shown that the hidden state of a special token in neural network models can encapsulate semantic information (Baudiš et al., 2016; Devlin et al., 2018). Furthermore, contemporary LLMs typically utilize the causal self-attention mechanism during both training and inference phases (Touvron et al., 2023a,b), attending on each prior token. This suggests that the final token in a sequence may be better suited to serve as a natural information compression point compared to other tokens, as they cannot observe future tokens. Therefore, a methodical approach that identifies and exploits sequence anchor tokens in a dependable and controllable manner is essential for compressing sequence information, effectively reducing keys/values caches, and improving inference efficiency for LLMs.
To this end, we propose novel Anchor-based Large Language Models (AnLLMs), equipped with an innovative anchor-based self-attention network (AnSAN) and an anchor-based inference strategy. The AnSAN is designed to compel the models to compress sequence information into the anchor token (the last token in our implementation) during the training process, with the aid of anchor-based attention masks. During inference, the anchor-based inference strategy retains the keys/values caches of anchor tokens, which have aggregated the entire sequence information, and discards those of nonanchor tokens, thereby reducing memory demands. Specifically, the anchor-based attention masks for AnSAN serve two objectives: 1) to ensure anchor tokens attend exclusively to tokens within the same sequence, preventing attention to other sequences, and 2) to direct non-anchor tokens’ attention to previous sequence anchors, blocking the other nonanchor tokens from previous sequences. It is noteworthy that the technique of anchor-based attention bears similarities to the principles underlying sparse attention (Child et al., 2019). However, unlike the existing research that employs sparse attention to extend the context length of LLMs (Chen et al., 2023; Ratner et al., 2023), our method focuses on continually pre-training the model to compress sequence information into the anchor token.
This paper is available on arxiv under CC BY 4.0 DEED license.