
Authors:
(1) Nora Schneider, Computer Science Department, ETH Zurich, Zurich, Switzerland ([email protected]);
(2) Shirin Goshtasbpour, Computer Science Department, ETH Zurich, Zurich, Switzerland and Swiss Data Science Center, Zurich, Switzerland ([email protected]);
(3) Fernando Perez-Cruz, Computer Science Department, ETH Zurich, Zurich, Switzerland and Swiss Data Science Center, Zurich, Switzerland ([email protected]).
Table of Links
2 Background
3.1 Comparison to C-Mixup and 3.2 Preserving nonlinear data structure
4 Experiments and 4.1 Linear synthetic data
4.2 Housing nonlinear regression
4.3 In-distribution Generalization
4.4 Out-of-distribution Robustness
5 Conclusion, Broader Impact, and References
A Additional information for Anchor Data Augmentation
4 Experiments
We experimentally investigate and compare the performance of ADA. First, we use ADA in an in-distribution setting for a linear regression problem (Section 4.1), in which we show that even in this case, ADA provides improved performance in the low data regime. Second, in Section 4.2, we apply ADA and C-Mixup to the California and Boston Housing datasets as we increase the number of training samples. In the last two subsections, we replicate the in-distribution generalization (Section 4.3) and the out-of-distribution Robustness (Section 4.4) from the C-Mixup paper [49]. In [49] the authors further assess a task generalization experiment. However, the corresponding code was not publicly provided, and a comparison could not be easily made.
4.1 Linear synthetic data
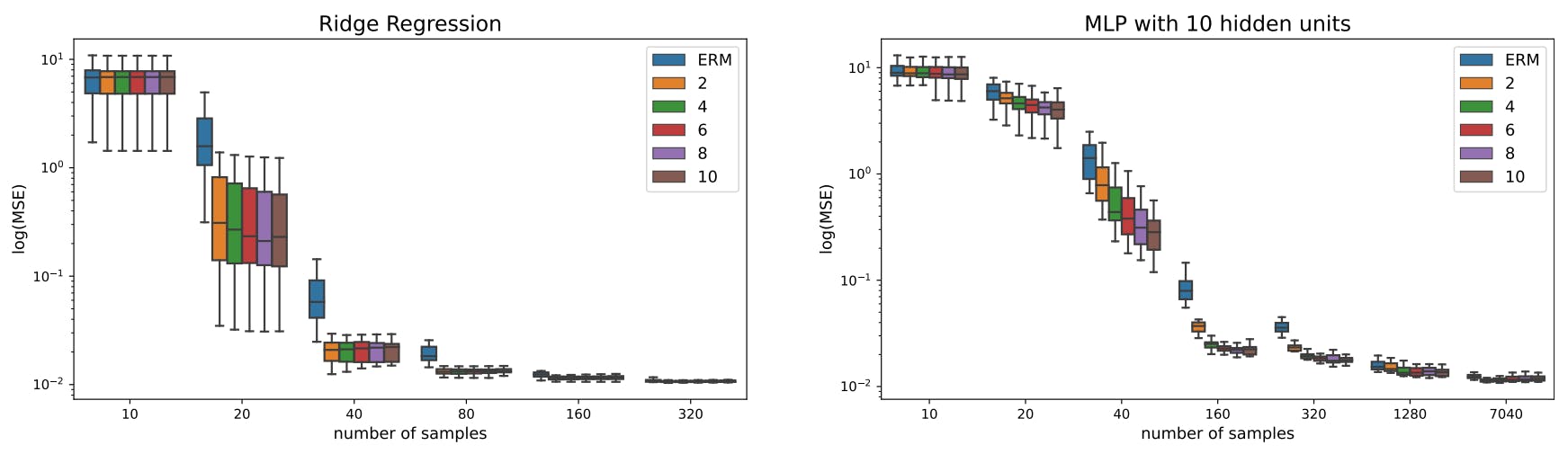
Using synthetic linear data, we investigate if ADA can improve model performance in an overparameterized setting compared to C-Mixup, vanilla augmentation, or classical expected risk minimization (ERM). Additionally, we analyze the sensitivity of our approach to the choice of γ and the number of augmentations.
Data: The generated data follows a standard linear structure

Models and Comparisons: We investigate and compare the impact of ADA using two different models with varying complexity: a linear Ridge regression and a multilayer perceptron (MLP) with one hidden layer and 10 units with ReLU activation. Using an MLP with more hidden layers shows similar results (see Appendix B.1 for details).

For the Ridge regression model, we increase the dataset by a factor of 10 by sampling from the respective augmentation methods and subsequently compute the regression estimators. In contrast, for the MLP, we implement the augmentation methods on a minibatch level. Specifically, we incorporate vanilla augmentation by adding Gaussian noise to each batch, apply C-Mixup after sampling from the beta distribution in each batch, and finally, apply ADA after sampling from the defined gamma values in each batch.

In summary, even in the simplest of cases, in which we should not expect gains from ADA (or C-Mixup), these data augmentation strategies provide gains in performance when the number of training examples is not sufficient to achieve the error floor.
This paper is available on arxiv under CC0 1.0 DEED license.