

Authors:
(1) Jianhui Pang, from the University of Macau, and work was done when Jianhui Pang and Fanghua Ye were interning at Tencent AI Lab ([email protected]);
(2) Fanghua Ye, University College London, and work was done when Jianhui Pang and Fanghua Ye were interning at Tencent AI Lab ([email protected]);
(3) Derek F. Wong, University of Macau;
(4) Longyue Wang, Tencent AI Lab, and corresponding author.
Table of Links
3 Anchor-based Large Language Models
3.2 Anchor-based Self-Attention Networks
4 Experiments and 4.1 Our Implementation
4.2 Data and Training Procedure
7 Conclusion, Limitations, Ethics Statement, and References
3.1 Background
Transformers. LLMs are primarily realized as decoder-only transformers (Vaswani et al., 2017; Touvron et al., 2023a,b), incorporating an input embedding layer and multiple decoder layers. Each layer contains a self-attention network and a feedforward network with normalization modules. Crucially, causal attention masks are employed, allowing tokens to attend only to preceding ones.
Self-Attention Networks. Typically for decoderonly LLMs like Llama2 (Touvron et al., 2023b), self-attention networks (SANs) map queries Q, keys K, and values V into an output, as delineated in the following equations,
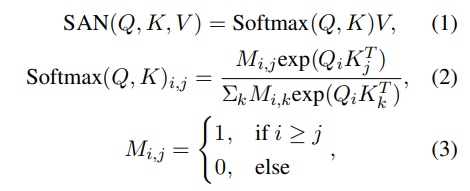
where M denotes an L × L masking matrix, facilitating the current i-th token to attend to only preceding tokens whilst disregarding subsequent tokens during the training and inference phases.
Keys/Values Caches. In the application of LLMs, the keys/values caches increase with lengthy prefix texts and continuously generated tokens during the inference phase, such as in question-answering (Saad-Falcon et al., 2023), text summarization (Basyal and Sanghvi, 2023), and machine translation (Pang et al., 2024). The key and value matrices associated with tokens of prefix inputs are cached to avoid recomputation and expedite subsequent token prediction (Radford et al., 2019). Additionally, the model generates the output token-by-token in the real-time inference process, which requires more cache memory to store the newly generated sequence. Therefore, addressing the challenges arising from the ever-expanding texts is crucial for enhancing the efficiency of LLM inference.
This paper is available on arxiv under CC BY 4.0 DEED license.